Neuigkeiten
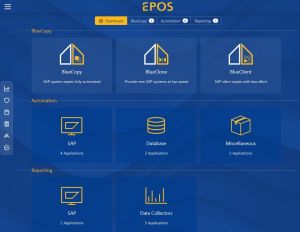
Neuerungen der WebUI im EPOS Server 23.11
Die neue WebUI erhält in letzter Zeit viel Lob! Wir wollen Ihnen die Neuerungen nicht länger vorenthalten und haben eine eine kleine Übersicht für …
Mehr erfahren
Die neusten Informationen für Sie zusammengefasst.
Die neue WebUI erhält in letzter Zeit viel Lob! Wir wollen Ihnen die Neuerungen nicht länger vorenthalten und haben eine eine kleine Übersicht für …
Mehr erfahren
SAP Reports lassen sich nun ganz einfach in den Ablauf einer SAP Systemkopie einbinden:
Mehr erfahren
BlueCopy und EPOS haben mit dem letzten Update weitere Konfigurationsparameter erhalten: Einschränkungen können nun auf Basis von Domänen und …
Mehr erfahren
Seit letzter Woche ist das neue Release verfügbar. Wir haben die wichtigsten Neuerungen für Sie zusammengefasst:
Mehr erfahren
Seit Neuestem sprechen wir immer wieder vom "EPOS Server" - aber was genau ist das denn und was verbirgt sich dahinter? In diesem Beitrag erklären …
Mehr erfahren
EIN EPOS Server – als Basis für alle EPOS Apps inkl. BlueCopy.
Mehr erfahren
Anfang Juni findet in Anlehnung an die alte CCC-Forum Tradition, das Competence Center Summit 2023 in Salzburg statt, und Empirius wird mit vor Ort …
Mehr erfahren
Ursprünglich als Fix-Releases geplant, sind in Version 10.3.5 und 10.3.6 nun auch einige neue Funktionen bzw. Vereinfachungen mit eingebaut worden.
Mehr erfahren
Fehlen bei Ihnen nach der Systemkopie im Zielsystem Transporte? Nicht mit dem neuen Addon QueueDiff für BlueCopy!
Mehr erfahren
Viele, viele Neuigkeiten haben wir in unser neues BlueCopy Release 10.3 gepackt! Schauen Sie gleich rein, was wir alles neu haben.
Mehr erfahren